Build scalable data pipelines to collect, clean, compute, and consume extensive data
Data engineering is the practice of designing and building systems for collecting, storing, and analyzing data at scale. H2HData Enterprise AI offers a data engineering system customized for your business needs

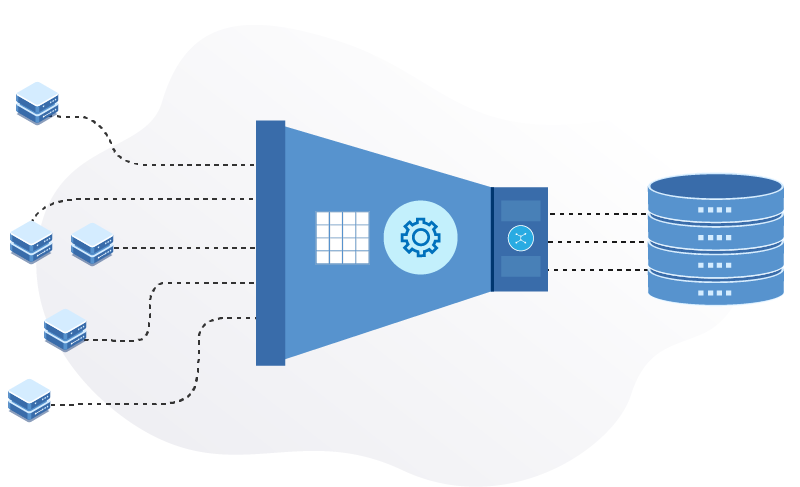
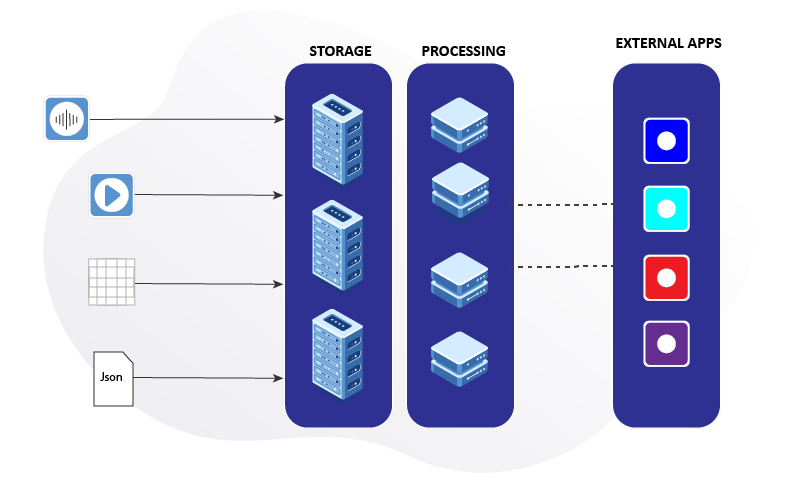
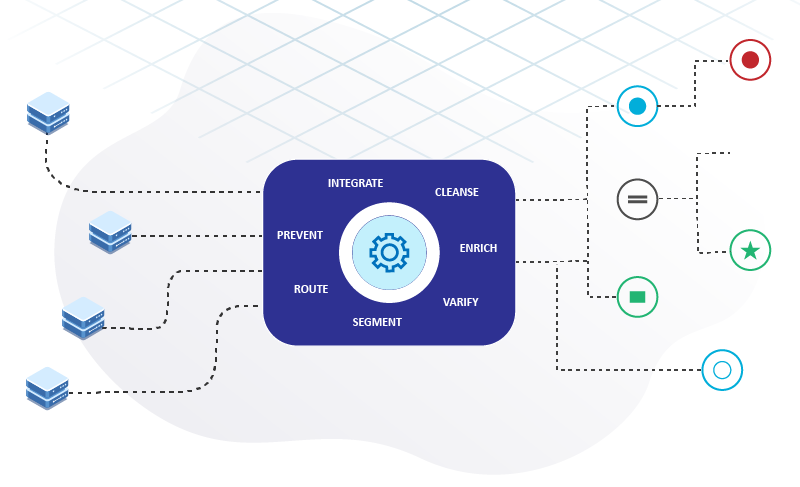
A data engineering system inputs raw data from legacy sources and uses distributed computation to process the ingested data. These distributed data pipelines are deployed on cloud, on-premises, and edge devices. A set of numerous conditional logic automates the use case-specific process flow, leading to monitoring, alerting, and reporting.
Developed data engineering systems can be easily integrated with other systems such as data warehouses, ERP, POS, sensors, software applications etc.
Tools/Technologies

You have to pick the right tool for the point you're trying to make and there is no one solution.
It is essential to have good tools, but it is also essential that the tools should be used in the right way. We are best at it !
Python
PySpark
Kafka
Airflow
Databricks
Snowflake
BigQuery
Redshift
dbt
Delta Lake
Spark
Postgres
Flink
NiFi
Hive
Presto
Hudi
Iceberg
Tasks/Techniques





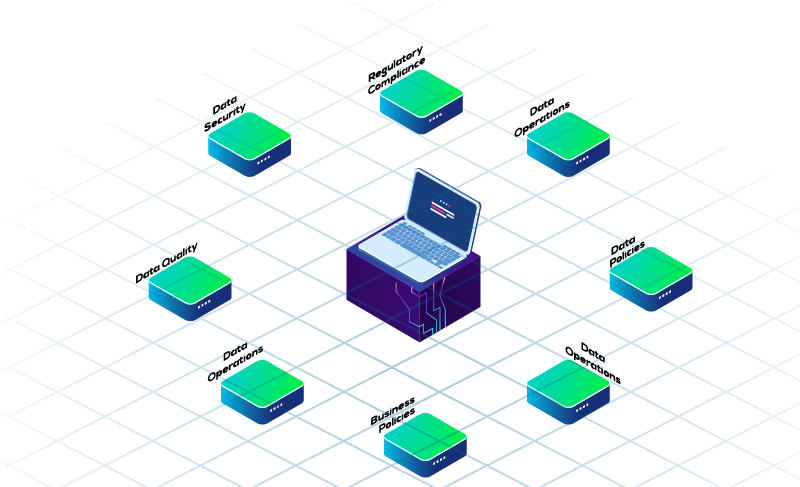



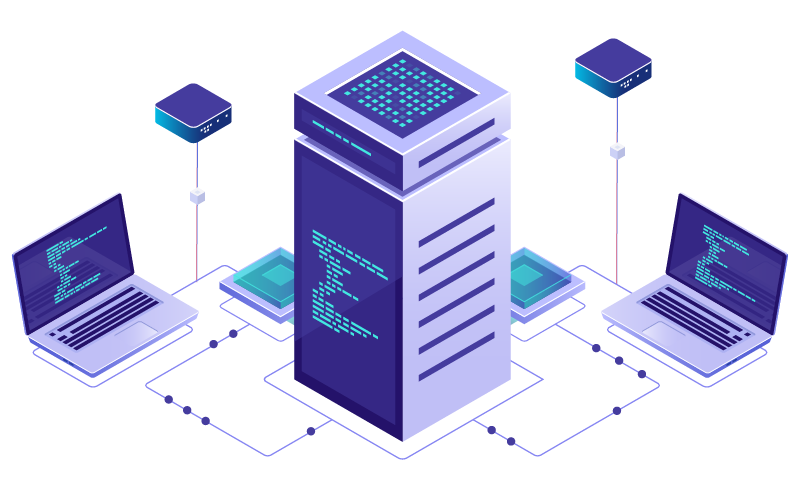


Types/Trials

We understand the complexities of modern markets and translate them into viable business solutions.
We have got required experience and proven expertise in designing, developing, and deploying complex use cases for various industries and functions
Realtime Bidding
IoT Infrastructure
Change Notifications
Personalization
Signal Procesing
Connected Vehicles
Sensors Analysis
Genomic Research
Predictive Maintenance
Network Capacity
Fraud Detection
Shipment Tracking